神器有没有!此文记录📝笔者捣腾tailscale的各种心得体会记录(其实就是碎碎念😓),欢迎大家讨论😄
2023.5.30
今天基本已经高效开始利用tailscale了,不免对这里面的原理感到好奇,于是尝试理解了一下,并将结果进行记录以方便未来查阅。
在一切开始之前,首先罗列未来可能可以阅读的内容:
Tailscale的子网路由和出口节点
How Tailscale works
Tailscale 开源版中文部署指南
客户端:
没啥说的,默认状态下客户端查看路由表(linux是ip route, macos是netstat -nr),即可发现与tailscale相关的内容均是被设置过导向其相关了
当运行exit nodes的时候,此时将会变成传统的vpn的模式,也就是路由表均由tailscale来接管了,很好理解,这样的话就完成了vpn通道的建立
服务端(exit node):
相较于客户端,服务端的行为和理解就有点复杂了,这里仅做目前为止的心得总结与猜测。
在服务端上查看路由表,会惊讶地发现,没有一丝tailscale的痕迹;
当使用nload查看流量的时候(此时客户端使用其作为exit node节点模式),会发现虚拟网卡tailscale0只有下载,没有上传;但是当查询eth0网卡的时候,便是像之前的代理协议一般,上传=下载;
除此之外,tailscale的运行现象还有:
- 网络流量是建立在软件层的虚拟的网卡,因为ifconfig可以查询到
- 在服务器上根本查询不到与tailscale相关的路由表。还有一个现象,虽然查询不到路由表,但是却可以直接ping或者访问到tailscale子网的内容,比如, ping astroslacker即可直接返回
- 当使用iftop等进行查看的时候,发现其在被客户端运行流量的时候,除了googledns,alidns这种,其余的都是被解析成ipv4的流量。
- 当客户端关闭Use tailscale DNS Settings的时候,客户端便不能上网啦,直接啥都上不去了。
之前我们本来推测,tailscale应该是在eth0上级直接接管了所有流量,然后再使用回传技术避免自己的流量被再次代理,从而实现服务端的全局route,但是问题来了,既然机器的路由表上级不是tailscale是机器自己内网实际存在的网关,这个网关tailscale肯定没有权限去接管,那么此种推测便不合理了。
所以,综上所述,结合上面的种种现象,我们推测,tailscale的服务端运行逻辑是,通过接管DNS的解析来判断具体的操作行为。通过判断DNS解析的情况,tailscale来甄别此条流量是否应该使用tailscale的网络,如果是的话,那么tailscale在软件层面将其导向虚拟网卡,这就是为什么路由表里没有其虚拟网卡,但是其依然可以访问虚拟子网设备的原因。
--> 2023.6.6,经过测试,可以输入以下指令查询到tailscale的路由表,搞乌龙啦(ˉ▽ˉ;)...
ip route show table 52
那么为什么客户端关闭了DNS设置,就无法使用此节点的exit node模式了?我们猜测,因为全局开启了MagicDNS,也就是tailscale在底层去连接子网设备的时候,其实是用过这种MagicDNS自定的域名去实现的。所以,如果不使用tailscale自带的100.100.100.100:53服务器,那么你就解析不了MagicDNS的结果,从而你就无法获得子网内exit node的ip,所以肯定连不上了哇...
tailscale逻辑:
尽可能保持网络原本的形状,其对应的协议、接口、行为等等,均努力对应上,软件需要做的就是打通各个子机,并让其通过软件虚拟网卡的形式,形成子网互联。
这种方式,相较于之前frp的内网穿透,你内网穿透再怎么弄也没办法像tailscale这样非常“自然化”的组网,毕竟frp只能做到流量转发,而tailscale直接“转发”了vpn到外界,然后多设备异地组网了
🐮🐮🐮!tailscale确实牛牛牛
开源服务端headscale:
客户端依然可以使用tailscale,而如果你有公网服务器,那么便可以用此服务器来搭建headscale开源服务端,从而实现子网互联。
2023.6.1
tailscale的DNS的理解
今日在发现,如果开启了客户端的tailscale dns的服务,那么在软路由环境+开启了预解析DNS方式的魔法透明代理的情况下,网络则可能无法连接,或者出现强烈卡顿。除此之外,还测试了MagicDNS的开启是否会影响到设备之间的互联的测试,现对目前发现的现象进行总结:
- MagicDNS并不会像之前猜测的那样,关闭了之后机器之间就无法互联了,其本质就是一个alias,方便用户直接通过hostname去连接设备,关闭并不会影响exit nodes的使用
- 如果想在上面所说软路由+DNS解析魔法的设备使用tailsclae的DNS,那么则需要在tailscale的网页后台的DNS处,自己手动加入你的preDNS服务器的地址,如下图所示:
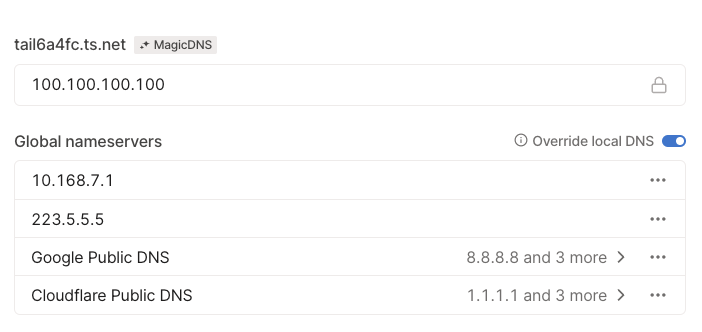
- 关于为什么客户端关闭了tailscale DNS,就无法使用exit node来连接互联网。一开始我想主要是因为设置里开启了"override local DNS"选项(之所以要开启这个,主要是因为列表中有Aliyun的服务器,而Aliyun的服务器的自带DNS网段与tailscale的100.100.100.100有冲突,详细信息可以参考:在阿里云机器上使用tailscale的dns错误排查)。不过,笔者也尝试过关闭override local DNS(Aliyun的机器上不了网,其他的可以),如果客户端不开启tailscale DNS,那么依旧无法使用exit node模式。从这点来看, tailscale的路由很大情况上依赖其自己的DNS解析服务,通过解析的方式便可以让其通道顺利连通。笔者也做了一系列测试,发现tailscale里面的机器,其域名是如*.tail6a4fc.ts.net这样的形式组成的。如下图所示,上面的图是在安装有tailscale DNS的机器上进行的,下面的是没有安装tailscale DNS的机器运行的
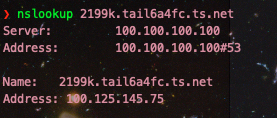
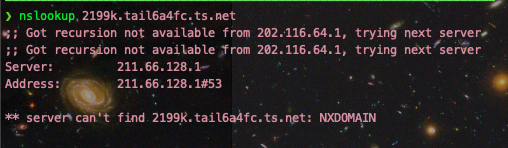
发现这个domain是tailscale自己专属的,所以你不开启其自己的DNS,那么你的机器肯定就解析不到位咯😓
综上所述,如果你想愉快的使用tailscale,以及其exit node等等模式,并且还想在透明代理的软路由下去使用,那么建议还是使用小猫咪🐱这种不会预解析DNS的软件来完成,这样不仅可以解锁比如chatgpt等功能,还可以确保DNS解析的结果属于节点所在的区域,并且还可以保证安全性,进一步防止DNS泄漏。
当然,如果你的设备是客户端,并且不需要开启exit node服务端,那么你完全可以,使用exit node的时候开启tailscale DNS,不用的时候把这个取消勾选☑️就好啦哈哈哈,皆大欢喜,简洁致美。
玄学部分
关于软路由魔法的分流域名解析,如果是白名单ip模式,国外DNS选择了比如谷歌等,这种就是一般的默认设置模式。在该模式下,所有到达分流器的请求均是ip形式,也就意味着实际上tailscale的DNS直接解了request的ip,然后再上报给软路由,这个逻辑是符合分流规则的,不知道为什么就卡的死死的,严重怀疑是魔法软件本身的问题,并且强烈质疑这种预解DN的合理性😠
2023.6.7
今天发现,tailscale直连打洞成功有一个很关键的设置,那就是机器的防火墙最好全局关闭...虽然说这会带来很多安全隐患,但是为了能够达到直连效果,只能这样了...并且,如果你tailscale的两台机器都拥有ipv6公网地址,那么这也会大大提升打洞成功率!
总之,开放所有端口给tailscale进行黑魔法自由发挥,或者你的两台需要凿隧道的机器都拥有ipv6地址,这两者都会大大提升直连打洞成功率
另外,当tailscale使用direct模式直接连接到海外公网ip的时候,此时如果使用了exit node模式,那么这种无异于使用魔法上网。如果tailscale在国内被普及了,那么此中方式的隧道将会被大概率关注了,所以最好还是小范围内使用最好,按需使用🤣
2023.6.8
今日尝试在openwrt下尝试搭建tailscale,以实现该局域网内所有设备均可访问tailscale组网设备。在经过尝试后,特总结此心得。
首先需要下载客户端,由于openwrt没办法安装预编译的东西(我自己的opkg很娇气,是这样的😓),所以去官网找到对应的架构即可,然后手动执行。执行指令如下:
# 开启tailscaled服务端服务,用于承载后续操作
nohup ./tailscaled --state=tailscaled.state > /dev_numm 2>&1 &
# 开启tailscale客户端服务,并添加子网、启动exit node模式,接受其他subnet的路由,让tailscale接管dns
./tailscale up --advertise-exit-node --advertise-routes=10.168.7.0/24 --accept-routes=true --accept-dns=false
请注意,这里--accept-dns=false,相当于是不使用tailscale的DNS了,为什么要这样呢?如果你这里设置了true,那么/etc/resolv.conf里面便会是100.100.100.100,当机器一切正常运行的时候还好,但是倘若你的机器断电重启了,那么tailscaled服务需要解析其自己的域名,此时100.100.100.100又用不了😓所以就会导致机器断网了...
那么为啥其他的linux就没这问题呢??推测应该是systemd写的比较好,应该已经预先想到了这种情况了,当然秉持一切从简的原则,这里就先暂时这样啦。请注意,关闭了dns,则可能导致此机器的exit node无法使用哦😄
开启、登陆之后,输入指令ifconfig,便可以查看到名称为tailscale0的虚拟网卡了,同时其还拥有自己的ip地址等等。但是此时笔者发现,openwrt下方的设备并不能ping通tailscale子网设备,于是就进一步设置:
- 首先在网络->接口 设置处,看看有没有
tailscale0接口,如果没有的话记得自己添加一个,不会添加的话请参考其他的接口的设置,比如eth0 - 在网络->防火墙设置处,(此处笔者并不是特别明白,而且第一次设置的时候玩蹦了,导致路由器里default路由表不见了,参照文章linux 添加 修改 删除路由才让openwrt恢复了网络连接😓),按照之前吃亏的经验...这里原则上应该将
lan转发出去的区域里,除了默认的wan和vpn,再增加tailscale0,然后路由器便会将子网设备的关于tailscale组网设备访问的请求根据相对应条件,三选一转发到接口tailscale0上了。
最终设置效果如下入所示:
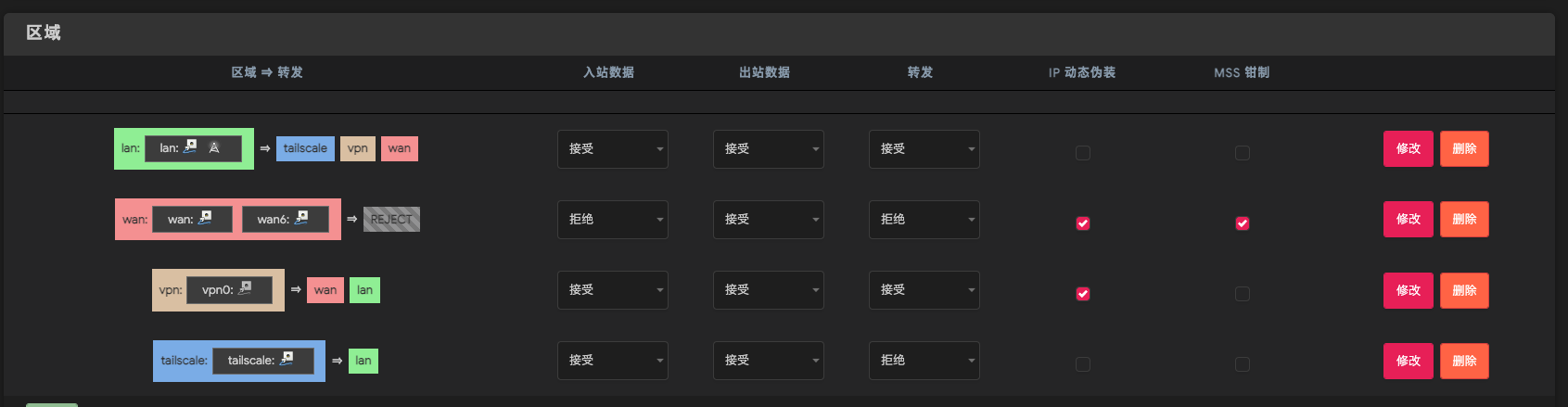
有趣的是,在笔者第一次玩蹦之后,重新设置好路由器路由表恢复网络之后嘞,并没有在接口处设置tailscale0,也没有在防火墙处lan的设置的出口增加tailscale0,但是内网设备已经可以完全访问tailscale组网了...不知道是咋回事,无语啦无语啦。总之一个原则,能跑通就可以,如果网络蹦了,记得参考上面连接自己手动去恢复一下路由表即可。
当在开启tailscale客户端的过程中,抛开重启无法重连的问题,如果我们加入了--accept-dns=true,这意味着tailscale将会修改openwrt的/etc/resolv.conf里的解析为100.100.100.100,登陆到openwrt后台,发现直接去ping MagicDNS的结果是完全可以的,ping tailscale组网设备的全域名也是没有问题ok的;但是,在妥善设置好路由器wan与lan接口的DNS后,在openwrt子网内的设备经测试,发现ping MagicDNS是不通的找不到host,但是ping 全域名则是可以的。这个现象说明:
仅限在安装了其客户端的endpoint上去使用
而像openwrt这种转发路由的行为,
其DNS只能为其子网内设备提供tailscale组网设备的全域名解析
相当有趣🤔️
2023.6.9
今日测试的时候发现,其实像openwrt这种使用tailscale的DNS,开启由于100.100.100.100这种找不到信息而启动不了,导致整个机器DNS错误上不了网的情况,实际上很有可能是因为openwrt自己的ntpd服务导致的。经过好几次测试,像r2c这种arm的🐤,由于没有备用时间电池,每次重启都会自动变成2016年,这就导致tailscale无法连接网络了...所以归根到底是时间的问题,逻辑如下:
死循环啦哈哈哈...所以,还是保险起见,设置`--accept-dns=false`咯
2023.6.12
今日发现,在某些节点上,exit node无法使用。这件事情很奇怪,使用工具比如nethogs去check网络的时候,其实可以看到各种请求都已经响应了,但是最终没有结果返回。当然,除了这些不太正常的节点外,其他的服务器是ok的。看到网上的文章说,有可能是因为防火墙的masquerode引起的,按照下方指令笔者初步尝试了一下,
# 添加tailscale0网卡至区域public中
firewall-cmd --zone=public --permanent --add-interface=tailscale0
# 开启masquerade
firewall-cmd --permanent --add-masquerade
firewall-cmd --reload
发现好像有那么点效果,但是在一些压根没开启firewalld的机器上,这肯定是么得用的😓。同时,还有一篇帖子也值得后续👀跟进跟进:No internet access with one Ubuntu exit node, POSTROUTING & MASQUERADE rule needed
除此之外,笔者也check了这些不太正常节点的DNS,其也是正常的,所以今日怀疑要么是因为机器设置的问题,要么就有可能是vps运营商进行了某种QOS?特此做记录📝,未来继续跟进💪
2023.8.13
总结一下这段时间的实操心得:
1. 机器如若想开启exit node,除了如2023.6.12所言那样要开启类似masquerode的东西(没有firewalld的机器就很麻烦,先搁置吧也不一定非要exit node 没有firewalld的请往下看,已经解决😁),还需要开启ip的转发权限,请注意,这个转发权限,如果你有ipv4/6双栈机器,那么这两个都要开,指令如下:
echo 'net.ipv4.ip_forward = 1' | tee /etc/sysctl.d/ipforwarding.conf
echo 'net.ipv6.conf.all.forwarding = 1' | tee -a /etc/sysctl.d/ipforwarding.conf
sysctl -p /etc/sysctl.d/ipforwarding.conf
这样的话基本上就可以了。为什么要开ipv6?因为现在运营商都给予了ipv6,而且操作系统层面一般也是ipv6优先,你的exit node机器不开启ipv6转发,那就用不了(别问我怎么知道的😓)
那么,经过测试,下方所说的自建的derp服务器是没办法与防火墙firewalld共存的,所以使用firewalld来进行masquerode开启便不适合搭建成derp的机器了。那么对于这一类(centos)机器,应该如何正常使用其exit node呢?其实只需要用iptables即可完成,参考文章如下:戳我1🙋 戳我2🙋,具体指令如下:
iptables -t nat -A POSTROUTING -o tailscale0 -j MASQUERADE
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# 保存,防止重启后失效
iptables-save
请注意,上面的eth0是你机器的公网出口网卡名称,请根据自己的实际情况进行修改。经过上述操作,就完成了机器不借助firewalld下开启masquerode转发了,你可以尽情使用exit node啦😄(甲骨文机器除外,其出口网卡是ens3,也是按如上设置,但是没啥用😓)
2. 如何搭建自己的derp服务器?笔者这里不过多赘述,有需要的朋友,请参考视频教程:🎥Tailscale玩法之内网穿透、异地组网、全隧道模式、纯IP的双栈DERP搭建、Headscale协调服务器搭建,用一期搞定,看一看不亏吧?。需要一提的是,视频里教程针对的是大陆没有备案的机器的纯ip的搭建方式,笔者实操已经成功;如果想利用DDNS来实现家庭动态公网带宽的derp,那么你就需要备案域名了😓后续操作如果有机会的话,笔者成功了的话再向大家总结😄
3. Tailscale可以配合parsec吗?在一些NAT过多,网络环境比较差的地方(没错我没有说校园网🤫),很可能parsec的P2P就过去不了,那么此时使用tailscale虚拟组网是不是就可以实现互联呢?经过笔者尝试,比如你有两个机器A和B,你想在B上当作parsec的客户端去连接A上的parsec服务端,但是仅仅实现A和B的tailscale虚拟组网是不行的,也不知道咋回事没道理...于是参考了一下这个文章:戳我🙋,上面说parsec配合zerotier以及另外一个啥Happyn是可以的,但是tailscale不行。简单粗暴一点,直接让B连接A的exit node服务,然后就可以了...😓不过一定要注意连接稳定性,因为A和B直接parsec不行就代表它们之间的连接需要借助derp了,反正我的测试下来是,不怎么稳定O_o体验差强人意吧
PS: 此问题得到了解决20231015:参考文章戳我🙋,因为tailscale的网段parsec不认,所以我们手动设置一下校园网内的windows机器的subnet即可,把172的那个网段映射到tail的子网中即可😄
4. Tailscale的ACLs怎么设置捏?其具体主要是来控制编写同/不同用户(组)的访问权限规则的,笔者目前还没有太多这个需求,所以先挖个坑,可以参阅的文章有:
2023.10.15
总结一下这段时间遇到的一些小问题,根据手写的现象来尝试分析一下留坑
现象(红字部分标记错误❌,不是现象3而是现象2):

分析猜测与总结:
现象1: 推测这应该是由于路由优先级导致的,在安装了tailscale的机器上,路由优先级应当是高于本机默认物理配置的,所以比如用机器A发起对172.16.209.60的请求,首先tailscale会将其路由到orchid,然后orchid会去寻找这个ip的真实地址,也就是aureum;同时如果用户想连接aureum,aureum也要响应coordinates服务器的需求,开始从自己的endpoint钻隧道打洞,那么问题就出在这了😓由于aureum又在tailscale的内网中,其endpoint段的172.16.209.60会被路由去orchid(或aureum本身或coordinates协调服务器),这就开始无限套娃了,所以这种方式不太可取。正确的做法是,orchid和aureum各自route各自的/32网络ipv4即可
现象2: 先补充一下:除了aureum和orchid出现这个问题,r2c也出现了,ping 10.168.7.1的时候不通。 综上所述,推测应该是tailscale处理请求行为“优化”导致的。如果你先tailscale ping sysu-aureum,那么coordinates服务器将会占用aureum的172.16的endpoint,其将会被用做联通网络,此时其内网subnet的属性将会被占据,那么可能tailscale认为你这个请求是关于联通服务器的而不是其subnet的,于是通道内可能没有加入subnet的route信息,所以导致ping 172.16.209.60不通;如果先tailscale ping 172.16.209.60或者ping 172.16.209.60,tailscale发现这是一个关于subnet的请求,所以tailscale会将172.16.209.60这个subnet联通信息加入隧道中加入类似白名单或规则的list里,从而让其实现子网互通...感觉这部分应该是tailscale没有写好(也不好说,因为home_Shunde的无论怎么来都ok,但是国外的机器la9929则可能会出现这个问题),应该无论哪种方式,子网信息都要保证能连接的😓不过anyway,养成好习惯,各种配置中,优先subnet的ip吧😄
现象3&4: 推测是因为tailscale如果链接依然持续这,即使是取消了subnet,route表里可能依然还是之前的还没更新(3389远程桌面一直映射到orchid服务器,即使subnet断了,短时间内route表可能还是让172.16走tailscale网络),所以导致关闭了orchid的advertise-routes后,self-rosso-win10还是连不上;至于为什么ipv4没办法拿去连orchid与self-rosso-win10的Direct呢?这里推测:由于orchid的ipv6实际上有路由,并不像那种只有内网ipv6的fe那种机器,其有公网ipv6,且有default gayeway,但由于之前说的路由表问题,导致信息出不去,所以tailscale就会判定Direct连不了,然后就自动选择derp服务器gz了...
补充现象: 当开启了orchid的derp服务器的时候,校内网(如orchid, aureum等)可以正常使用orchid-derp互通;而校外网(如coal-guangzhou, amore等)直连不上orchid-derp(毕竟derper需要开启STUN完全关闭防火墙等才可连接,被动的ipv6别想了)。此时如果从coal-guangzhou主动去给orchid/aureum打洞,则就通不了了,因为orchid/aureum附近最近的derper是orchid,而这个derper是coal-guangzhou无法连接的。这里的原因应该是因为tailscale在打洞伊始先调用目标机最近的derper实现互联,然后再去coordinate打洞尝试直连,而像上面说的这种例子,coal-guangzhou无法连接到orchid的derper,所以导致打洞进程直接堵死...这样说的证据就是,当使用orchid去向coal-guangzhou打洞的时候,则可以打通了,因为离coal-guangzhou最近的derper gz,双方都可以连上😓这也是tailscale算法有待优化的地方,其应该增加判断,比如某种方式不通,则依次尝试其他方式和其他derper等等...
总的来说,tailscale毕竟是与物理网络交汇的虚拟网络软件(甚至很多时候虚拟与物理共存交错),存在有这些bug也在所难免,做为个体用户,平时多总结多试错,然后避开这些可能引起问题的“玄学”情况即可啦😄
2023.10.19
发现orchid机器的ipv6又掉了,不知道是学校交换机的问题还是centos8(这***系统一直不让人省心)的问题,总之ipv6掉了后,就像之前分析的,orchid又advertise了172.16网段,导致直接连不上,或者连上的话只能走derp服务器了,这样太耗流量了,关键是在校内仅仅因为没ipv6导致tail无法direct,然后跳到derp再回来,这么弄实属没必要了... 所以--->索性直接关闭了orchid的tailscale服务,然后用aureum去advertise之前orchid的172.16...252网段,随后调整各种内网服务,均设置为172.16的网段而不是tailscale的网段(这样也是为了更好地适配以后的配置)
所以哇,无奈😮💨但也没啥好办法,先这样整吧,大概率怀疑是centos8系统的问题丢失了ipv6或是之前的ipv6路由不稳定,愈发觉得ubuntu是真的顶!
阶段性总结:
经过了这段时间围绕orchid服务器的“折磨”,也从种种乱象中理出来了某些接近真相的真相,现总结如下:
1. 当机器advertise了内网的subnet,比如172.16../32之后,这个ip将会被“占据”,也就是优先级更高;这是什么意思呢?也就是tailscale的机器,tailscale设置的route table优先级会高于机器自身的路由表。比如在校园网内,明明可以直接连接到172.16的orchid,但是由于其在tailscale内被subnet路由了,所以mac就开始走tail内部网络去寻找172.16的orchid(显然直连的ipv4网段找不到,毕竟在mac和tailscale看来这个东西是内部subnet);如果此时orchid有ipv6,那么很简单,就会直接用ipv6的endponit来承载这份Direct了...但是如果ipv6有问题了,那么便只能通过tailscale内部的derp服务器连接了
2. 基于上面👆第一点的分析,tailscale占据了172.16的orchid通道,不过原则上来说,对于拥有公网ipv4的机器,比如yhz,还是可以连接到orchid的,通过58.249..网段即可,毕竟这个endpoint并没有被加入subnet中,是自由的
3. 可以做几个小实验,来验证一下目前理论的准确与否:
- mac用朱总的路由器的网,因为其没有ipv6,尝试直接去连接aureum,原则上来说由于172.16被占用,此时是无法在校园网内Direct的而是会通过gz的derp来连接
- 再次开启orchid,然后用aureum来route它的172.16,看看是不是跟预料的一样,校园网内设备无法连接(无论是172.16网段还是100.网段),但是外部设备则可通过100.网段连接orchid
- 开启orchid,测试yhz是否可以Direct到其ip
- 在家里或宿舍的网络环境中,小mac开启tailscale,原则上来说此时网关是10.168.1.1(或宿舍的10.168.7.1),这个被路由器上的tailscale给subnet了,但小mac要想上网,流量需要被路由到10.168.1.1,根据之前的分析,这个链路是过不去的,或者是会跳到derp连接,所以小mac上不了网...当关闭了tailscale preference里的subnet后网络恢复正常
目前没想明白的问题:为什么orchid在admin console取消了172.16的subnet,aureum和mac等校园网内设备依然无法连接到172.16呢(已经询问过chatgpt,大概率没有路由表缓存)?
后续笔者会抽时间验证上述实验,并根据结果进行进一步总结,已经完成的实验用删除线直接划掉就好😄